

Sports betting constantly evolves, and staying ahead means finding new angles to get an edge. One exciting approach is to blend the power of predictive modeling with real-time odds data and insights from the sharpest sportsbooks in the market. You are using the implied probability of the no-vig odds to enrich your strategy with the expertise of the market’s sharpest bettors, making your predictions more responsive to current market conditions. It’s a way to level up your handicapping by integrating technology and expert knowledge, making the complex world of sports handicapping more approachable and rewarding. Let’s explore how leveraging this sophisticated combination of predictive modeling and no-vig insights can transform your approach to sports trading, offering a sharper edge and more thoughtful decision-making.
The Model: Pythagorean Expectation
For this article, we’ll employ an Excel model I’ve created. Utilizing Excel allows for meticulous control over each aspect of the model. It is beneficial to pilot-test a concept in Excel before advancing to more complex programming. This step-by-step approach aids in refining the logic and ensuring accuracy before coding the model using R.
For those unfamiliar, R is a programming language designed specifically for statistical analysis and data visualization. It’s particularly powerful in sports modeling because it can handle large datasets and perform complex statistical computations efficiently. While R is an excellent tool for in-depth sports analytics, we’ll focus on Excel to simplify the process in this instance.
To contextualize our model, we’ll focus on the NBA, utilizing what I call the nbaPE model. This model adapts the Pythagorean Expectation formula — initially developed by Bill James for baseball — to basketball. The Pythagorean Expectation is a statistical formula that estimates the expected win percentage based on the number of points scored and points a team allows. By applying this principle, we can derive insightful predictions about team performance, offering a strategic basis for our betting decisions.
To begin calculating each team’s Pythagorean Expectation (PE), we first compile the results of every game played this season. A notable advantage of this model is its simplicity in data requirements, relying only on game results for its initial calculations. Later, we’ll integrate live odds data to enhance the model’s applicability.
The process starts by summing the total points scored by each team, both at home and away, and the points allowed to their opponents. We obtain a comprehensive picture of each team’s offensive and defensive performances by aggregating the points scored and allowed. Next, we tally the total number of games each team has played and won. These statistics provide the necessary inputs to calculate each team’s Pythagorean Expectation.
The Pythagorean Expectation formula is given by: PE = Points Scored ^ 2 / Points Scored ^ 2 + Points Allowed ^ 2. This formula estimates a team’s expected winning percentage based on their scoring efficiency relative to their opponents. The key to adapting this model for basketball lies in determining the optimal exponent factor, which varies from sport to sport.
Our Excel model uses the solver tool to fine-tune the exponent factor. The solver tool allows us to minimize the Mean Squared Error between each team’s actual win percentage and their Pythagorean Expectation by adjusting the exponent factor used in the formula. By changing the exponent in the formula, we refine the model to fit the dynamics of basketball better, ensuring that our predictions are as informed and accurate as possible. I have this run for us, and after running the solver tool, we get a PE Exponent of 14.2214833.

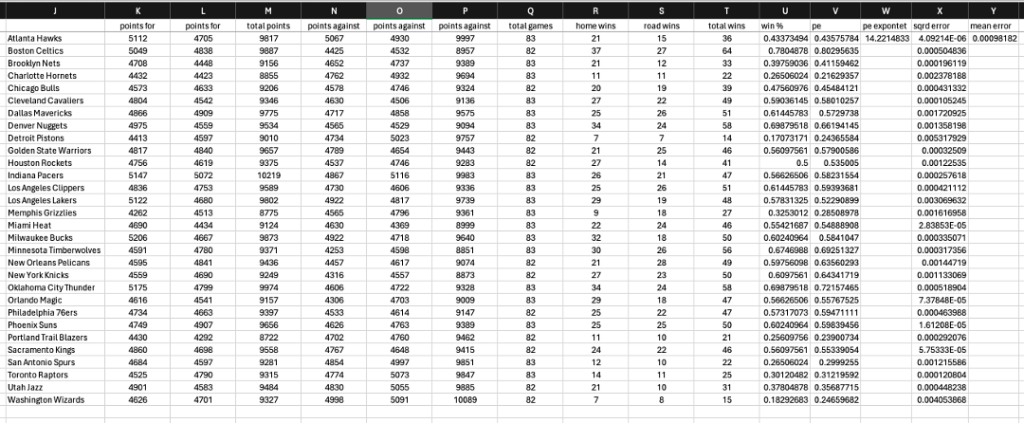
With each team’s Pythagorean Expectation (PE) calculated, we can use these figures to estimate the probability of one team defeating another. The primary method involves dividing a team’s PE by the sum of both teams’ PEs. This calculation provides a straightforward probabilistic expectation based on their relative performance metrics.
Instead of the more straightforward approach, I use a Logit Function to convert each team’s PE to a logarithmic scale. The benefit of the Logit Function is its ability to transform our PE values into a format that better handles extreme values and probabilities. This transformation helps mitigate the impact of outliers and ensures a more normalized data distribution.
Next, we compute the difference between each team’s logarithmically transformed PEs and convert this difference back to a probability using a logistic function. This method is beneficial as it allows for a more refined analysis of the likelihood of outcomes, considering the nuanced dynamics between the competing teams. By calculating this for both teams, we establish a model that predicts the probability of one team beating another with enhanced precision. Below, we select Indiana and Milwaukee and based on each team PE, we get a probability of 50.1% for Milwaukee and 49.9% for Indiana.


Incorporating Market Data into Our Model
Having established a model that predicts the probability of outcomes between two NBA teams, we now face the challenge of incorporating more dynamic and contextual data, such as player injuries or weather conditions, which could significantly impact game results. While Excel offers a solid foundation for statistical analysis, its capability to handle real-time and multifaceted data is limited.
Having established a model that predicts the probability of outcomes between two NBA teams, we now face the challenge of incorporating more dynamic and contextual data, such as player injuries or weather conditions, which could significantly impact game results. While Excel offers a solid foundation for statistical analysis, its capability to handle real-time and multifaceted data is limited.
To address this limitation, we can manually integrate this data using the logistic transformation method previously detailed, alongside leveraging the capabilities of OpticOdds’ Odds Screen. This platform allows us to monitor live odds from various sportsbooks, providing a rich, real-time dataset that can be crucial for our analysis. Below is a screen shot taken from the OpticOdds’ Odds Screen.


This practice aligns with the Efficient Market Hypothesis, which suggests that market-maker sportsbooks, when their odds are converted to implied probabilities and adjusted to remove the hold, can reveal what the market collectively assumes about the actual likelihood of an event’s outcome. By incorporating these no-vig implied probabilities into our model, we can enhance our predictions with insights that reflect current market sentiments and the latest event-affecting developments.
Pinnacle is recognized as a market maker in the sports betting industry and is known for its sharp lines. We integrate this expertise into our model to capture market sentiment more accurately. I typically start by entering the American odds and converting them to decimal odds, which helps illustrate the process for those unfamiliar with decimal formats. But you can skip this step and start with the decimal odds.
The conversion to implied probabilities is straightforward: Implied Probability = 1 / Decimal Odds. This calculation is crucial as it provides the foundation for the next step—adjusting these probabilities to account for the vig. By normalizing the team’s implied probability against the sum of both teams’ implied probabilities, we derive the no-vig odds, which reflect a purer measure of the market’s expectations.
Incorporating these market-derived probabilities enhances our model’s accuracy, providing a deeper insight into how the betting landscape perceives each matchup. Below, we take the odds from Pinnacle and remove the hold. We get a no-vig probability for Milwaukee of 54% and for Indiana of 46%.


We apply the previously used logit transformation to integrate the market’s no-vig probabilities into our model. We start by converting both teams’ no-vig probabilities and our model’s probabilities to a logarithmic scale. This alignment on a log scale allows us to manage and compare the data. Once we have both probabilities in log form, we compute the average of these logarithmic probabilities. These averaged log values are then converted to a probability using the logistic function, giving us the final probabilities for one team beating the other. These final probabilities represent our fair market value odds for the event, offering a refined assessment of potential outcomes. For out game between Indiana and Milwaukee, our fair market odds based on our model and Pinnacle’s no-vig odds, we have a final probability for Milwaukee of 50.9% and for Indiana of 49.1%.


These fair market value odds are a benchmark, allowing us to compare our model’s predictions against the broader market. Utilizing the OpticOdds Odds Screen, we can further analyze how our odds stack up and make informed decisions when setting odds in the market. This process enhances our strategic approach and reinforces our position by aligning our model with real-time market dynamics.
Final Thoughts
This article explored enhancing sports betting strategies by integrating predictive modeling with real-time market data. Starting with a basic Pythagorean Expectation model in Excel, we expanded our approach by incorporating no-vig probabilities derived from Pinnacle’s market-leading odds utilizing the OpticOdds Live Odds Screen. This allowed us to calculate fair market value odds, providing a robust basis for comparing our model’s outputs with the broader market.
Looking ahead, there is significant potential to refine and automate this process further. By leveraging OpticOdds’ AI Algorithm odds and their comprehensive API, we can transition our model from Excel to a more dynamic platform. Automating the model not only streamlines the data processing and odds calculation but also enhances the responsiveness of our betting strategies to real-time market changes and variables such as player injuries and weather conditions.
This evolution from a manual to an automated system could drastically improve efficiency and accuracy, positioning users at the forefront of sports betting analytics. By harnessing the power of OpticOdds’ technologies, bettors can gain a sharper edge and make more informed decisions in the ever-evolving landscape of sports betting.


